Retrieval-augmented generation (RAG) is increasingly recognized as an effective approach for mitigating the hallucination of large language models (LLMs) through the integration of external knowledge. While numerous efforts, most studies focus on a single type of external knowledge source. However, in real-world applications, most situations involve diverse knowledge from various sources, yet this area has been less explored. The main dilemma is the lack of a suitable dataset containing multiple knowledge sources and pre-exploration of the associated issues. To address these challenges, we standardize a benchmark dataset that combines structured and unstructured knowledge across diverse and complementary domains. Based on this dataset, we further develop a plug-and-play RAG framework, PruningRAG, whose main characteristic is to employ multi-granularity pruning strategies for optimizing the integration of relevant information and minimizing misleading context. Building upon the standardized dataset and PruningRAG, we also report a series of experimental results, as well as insightful findings. Our dataset and code are publicly available here, with the aim of advancing future research in the RAG community.
Overview of PruningRAG
Benchmark Evaluation of RAG
Table 1: Comparative analysis of RAG performance across different external knowledge.
External Knowledge
Method
Acc.
Halluc.
Miss.
Score
None
LLM-Only
15.61%
20.42%
63.97%
-4.81%
5 Web pages
Naive RAG
7.51%
8.68%
83.81%
-1.16%
HyDE
24.36%
17.72%
57.91%
6.64%
PruningRAG
27.64%
18.16%
54.19%
9.48%
Mock API
Naive RAG
8.53%
1.60%
89.86%
6.93%
HyDE
19.84%
11.09%
69.07%
8.75%
PruningRAG
29.03%
10.86%
60.10%
18.16%
5 Web pages + Mock API
Naive RAG
15.10%
7.95%
76.95%
7.15%
HyDE
22.07%
21.88%
56.09%
0.15%
PruningRAG
44.64%
17.58%
37.78%
27.06%
50 Web pages + Mock API
Naive RAG
14.22%
8.90%
76.88%
5.32%
HyDE
32.68%
19.69%
47.63%
12.99%
PruningRAG
38.73%
14.59%
46.68%
24.14%
Empirical Study
Coarse-Grained Knowledge Pruning
Table 2 evaluates four knowledge utilization strategies: relying solely on internal or external knowledge, combining internal and external sources, prioritizing internal knowledge before external retrieval, and a proposed pruning-based method. The results show that using multiple sources simultaneously often introduces conflicts, while prioritizing internal knowledge can lead to hallucinations. The pruning-based strategy dynamically selects relevant sources per query, optimizing knowledge integration and improving overall performance.
Table 2: Comparison of performance of different strategies for leveraging knowledge sources.
Experiment Setting
Acc.
Score
LLM
17.94%
-0.36%
Web pages
27.64%
9.48%
Mock API
34.43%
24.43%
Both
40.26%
18.31%
LLM+Web pages
17.94%
7.80%
LLM+Mock API
40.55%
22.25%
LLM+Both
45.73%
14.37%
LLM → Web pages
25.30%
-5.84%
LLM → Mock API
35.01%
11.31%
LLM → Both
38.22%
6.64%
Knowledge Source Pruning
40.34%
27.72%
Fine-Grained Knowledge Pruning
Retrieval is a crucial step in the RAG process. In this subsection, we analyze different retrieval techniques and their performance in extracting relevant information from knowledge sources. We also explore the trade-offs between speed and accuracy in various retrieval methods.
Table 3 compares PruningRAG with and without an initial broad retrieval step. The broad retrieval stage enhances efficiency by filtering large external knowledge volumes, reducing latency, and improving precision in the subsequent focused retrieval. This multi-stage pruning approach optimizes both relevance and speed for effective knowledge extraction.
Table 3: Comparison of effectiveness and efficiency with and without broad retrieval.
Setting
Acc.
Hall.
Latency (s)
Broad Retrieval (w/)
28.96%
25.09%
3.29
Broad Retrieval (w/o)
28.95%
24.36%
33.54
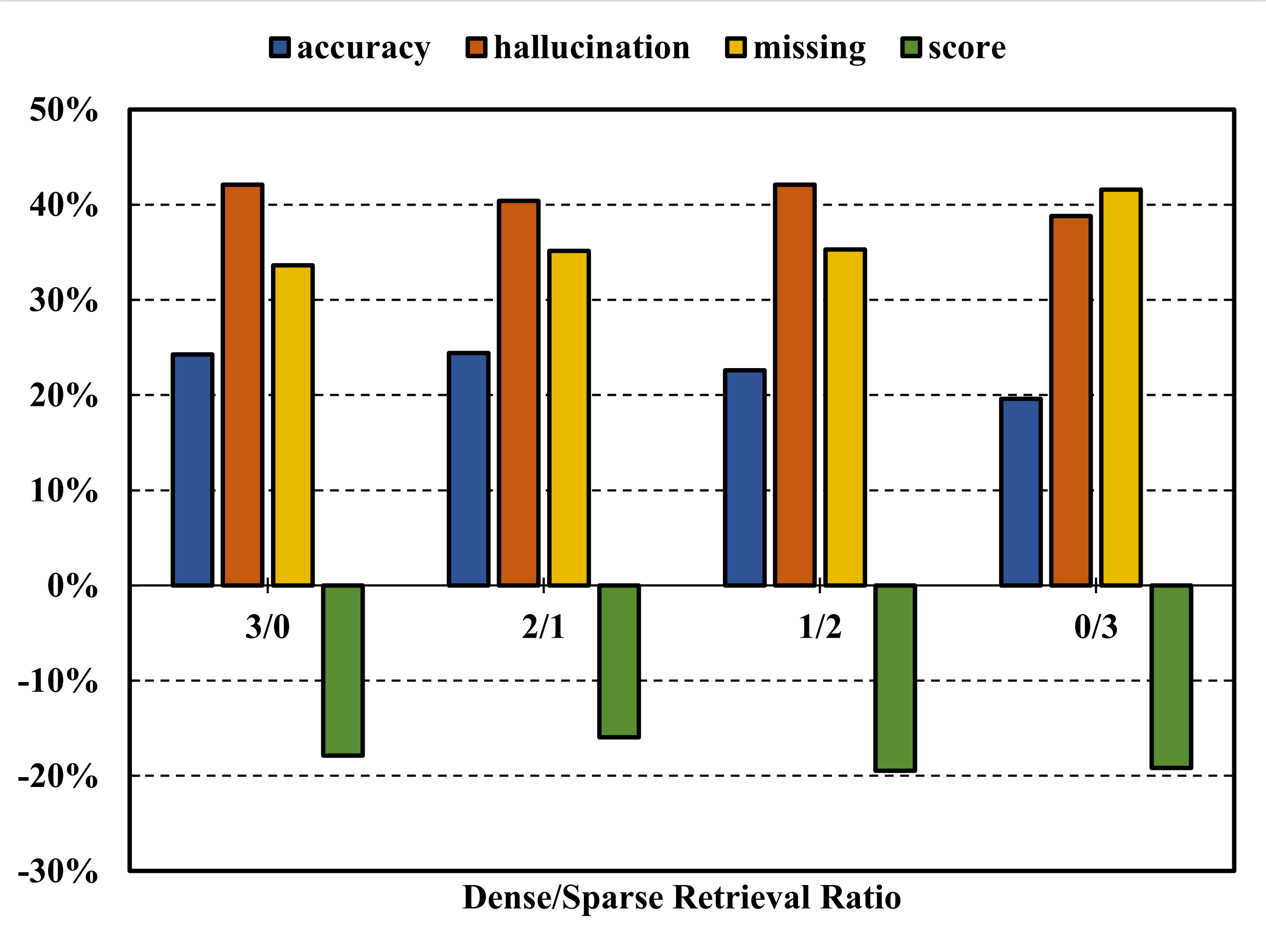
Figure 1 highlights the superiority of dense search over sparse search due to its ability to capture semantic relationships. While combining dense and sparse search improves accuracy compared to sparse search alone, it also increases hallucinations, indicating challenges in pruning misleading context effectively.
Figure 1: Performance of varying retrieval methods in RAG.
Table 4 evaluates re-ranking configurations in PruningRAG, showing that increasing retrieval blocks slightly improves accuracy but raises hallucination rates. This highlights the reranker's limitations in pruning misleading information, emphasizing the importance of the preceding retrieval process.
Table 4: Performance of reranker configurations in RAG.
Config.
Acc.
Halluc.
Miss.
Score
(3, 3)
24.14%
20.42%
55.43%
3.72%
(3, 5)
23.85%
22.68%
53.46%
1.17%
(3, 10)
24.51%
23.05%
52.44%
1.46%
(3, 20)
25.38%
23.34%
51.28%
2.04%
(3, All)
25.46%
23.41%
51.13%
2.04%
Note: (3, X) denotes retrieval of X chunks, with (3, All) indicating all chunks passed directly.
Knowledge Reasoning
In this subsection, we analyze the impact of our strategies for enhancing LLM utilization and reasoning over pruned knowledge, including Chain-of-Thought (CoT) reasoning, In-Context Learning (ICL), noise chunk fusion, query placement in prompts, and our confidence detection strategy.
Knowledge-enhanced prompt.
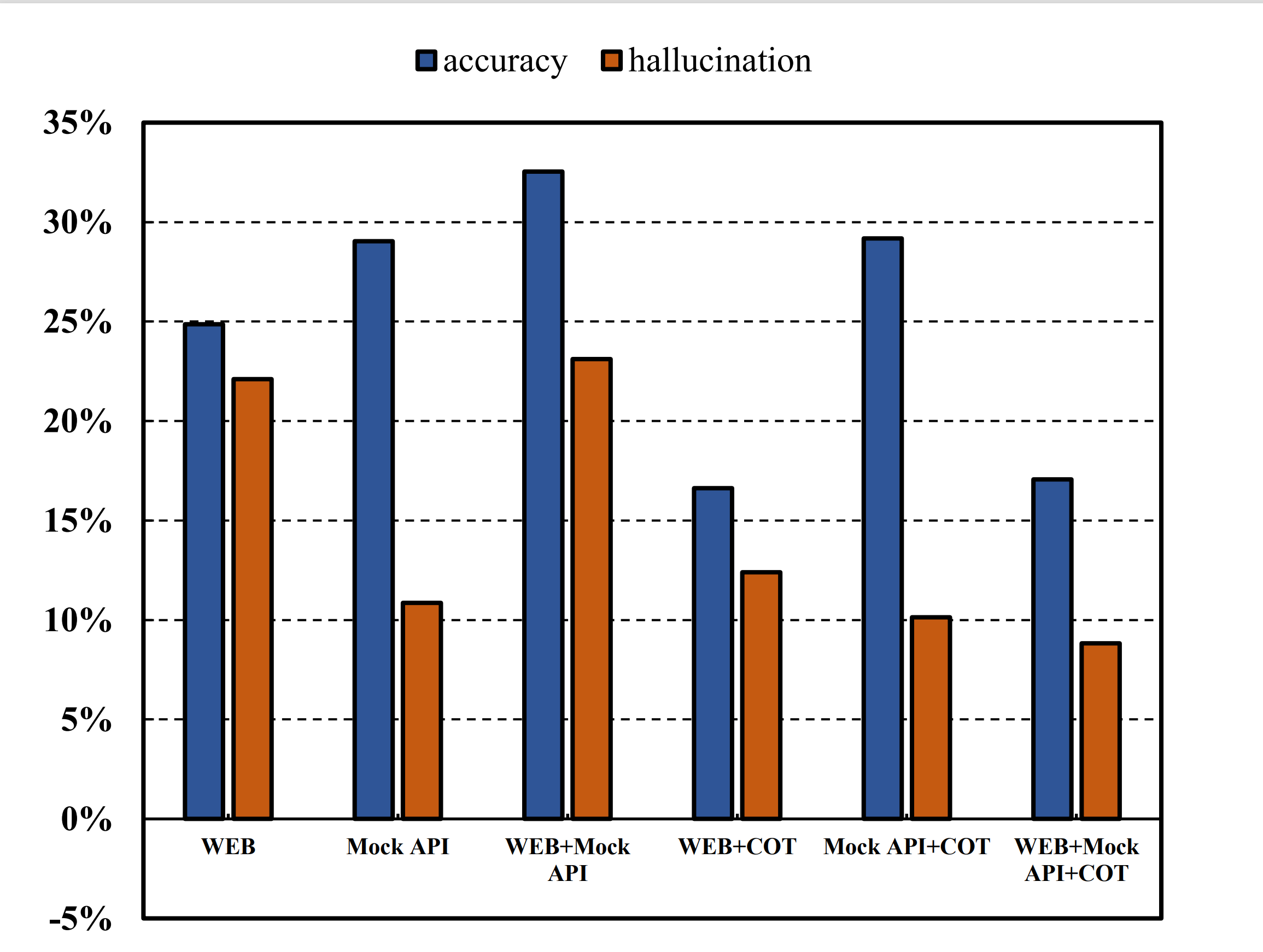
Figure 2 illustrates the impact of CoT reasoning in PruningRAG, depending on external knowledge quality. With noisy, unstructured data, CoT effectively filters irrelevant information and reduces hallucinations, improving accuracy. However, with reliable API-based sources, CoT's cautious multi-step reasoning may lower accuracy despite reducing hallucinations, highlighting a trade-off between precision and conservatism.
Figure 2: Impact of CoT across knowledge sources.
Table 5 examines the effect of false premise examples on LLM performance in PruningRAG. Few-shot examples improve overall task comprehension and reasoning but reduce accuracy on false premise questions compared to zero-shot. Cross-domain examples outperform domain-specific ones, mitigating overfitting and enhancing reasoning through greater variability.
Table 5: Impact of few-shot learning on LLM reasoning.
Category
N
Acc.
Hall.
Miss.
Score
Overall
0
13.20%
10.50%
76.29%
2.70%
1
16.05%
12.62%
71.33%
3.43%
2
16.12%
12.98%
70.90%
3.14%
3
15.17%
12.69%
72.14%
2.48%
1*
16.12%
11.89%
71.99%
4.23%
2*
18.02%
11.23%
70.75%
6.78%
3*
16.41%
11.60%
72.00%
4.81%
False Premise
0
25.00%
5.77%
69.23%
19.23%
1
16.03%
14.10%
69.87%
1.93%
2
16.57%
13.46%
69.87%
3.11%
3
17.31%
12.82%
69.87%
4.49%
1*
20.51%
12.18%
67.31%
8.33%
2*
19.87%
11.54%
68.59%
6.33%
3*
23.08%
9.62%
67.30%
13.46%
Note:N* indicates that the N examples provided for in-context learning are cross-domain examples.
This experiment evaluates the PruningRAG system's performance under various confidence evaluation strategies and prompt instructions to mitigate hallucinations. Two prompts were tested: one without guidance and another instructing the model to respond with "I don't know" when uncertain. Confidence methods included context sufficiency, entropy-based evaluation, and their combination.
As shown in Table 6, instructing the model to say "I don't know" reduced hallucinations across all methods, albeit with a slight drop in accuracy due to increased caution. Entropy-based evaluation combined with explicit prompts achieved the best balance, minimizing errors while maintaining performance. Combining both checks produced conservative responses, ideal for high-stakes scenarios, while entropy-based evaluation with prompts offered a balanced solution for general use.
Table 6: Performance comparison of confidence evaluation methods.
Confidence Eval
Acc.
Hall.
Score
None (w/o inst)
44.78%
55.14%
-10.36%
Context Check (w/o inst)
30.71%
18.17%
12.55%
Entropy-Based (w/o inst)
42.23%
43.11%
-0.88%
Combined (w/o inst)
29.03%
15.54%
13.49%
None (w/ inst)
31.87%
12.25%
19.62%
Context Check (w/ inst)
26.40%
10.21%
16.19%
Entropy-Based (w/ inst)
30.49%
10.36%
20.13%
Combined (w/ inst)
24.73%
9.04%
15.68%
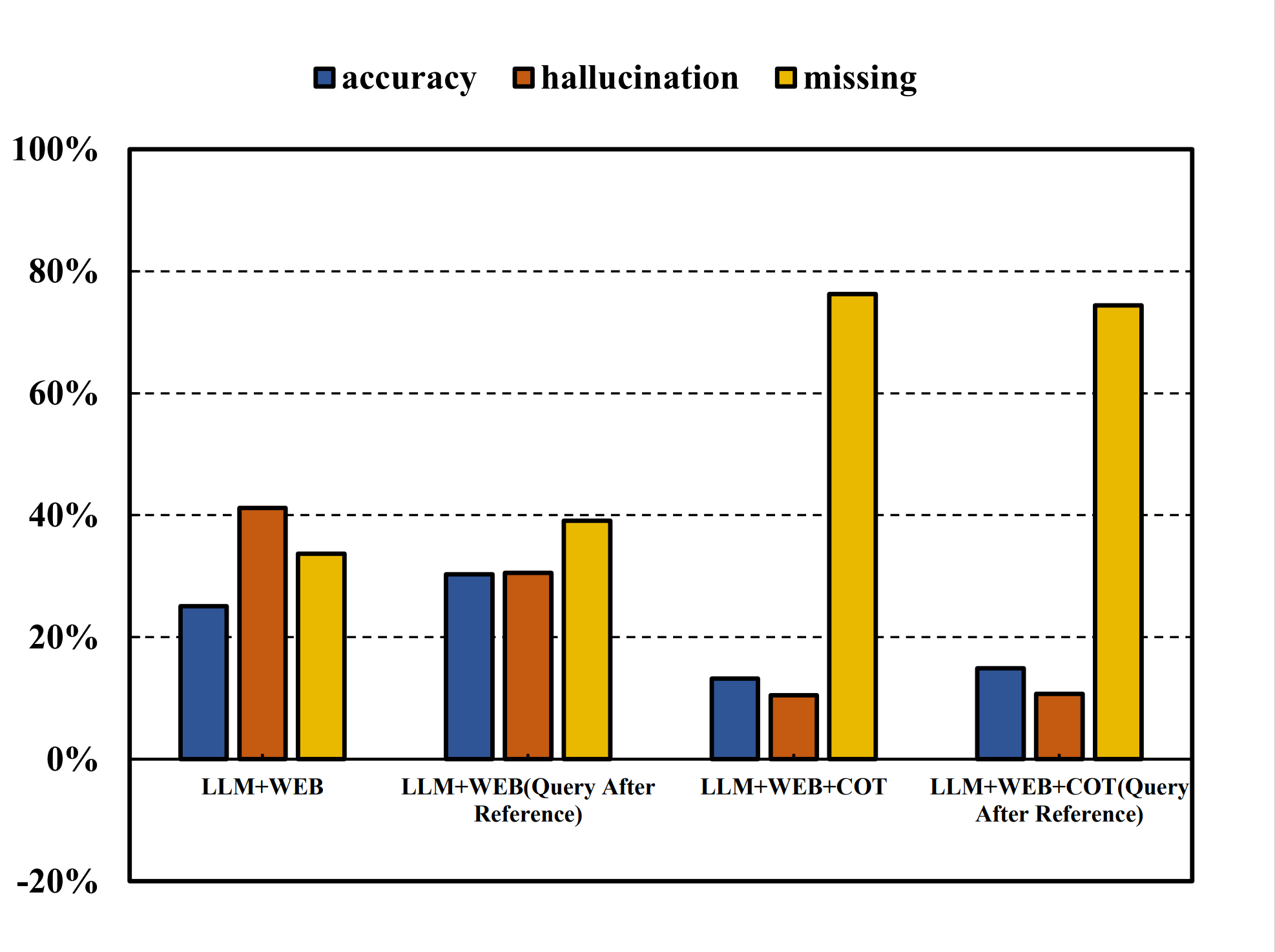
Figure 3 highlights the importance of query positioning in prompts. Placing the query after the pruned context improves accuracy and reduces hallucinations, as the model benefits from full context before responding. This avoids the "query forgetting" effect in lengthy contexts, emphasizing the need to position queries after extensive retrieved information for optimal response quality.
Figure 3: Impact of query position within prompt.
Figure 4 shows the impact of noise chunks in PruningRAG. Moderate noise improves accuracy and performance by priming the model to distinguish relevant from irrelevant information. However, excessive noise degrades performance, underscoring the balance needed for optimal results.
Figure 4: Performance comparison based on noise chunk quantity in RAG.
Hyperparameter Sensitivity Analysis
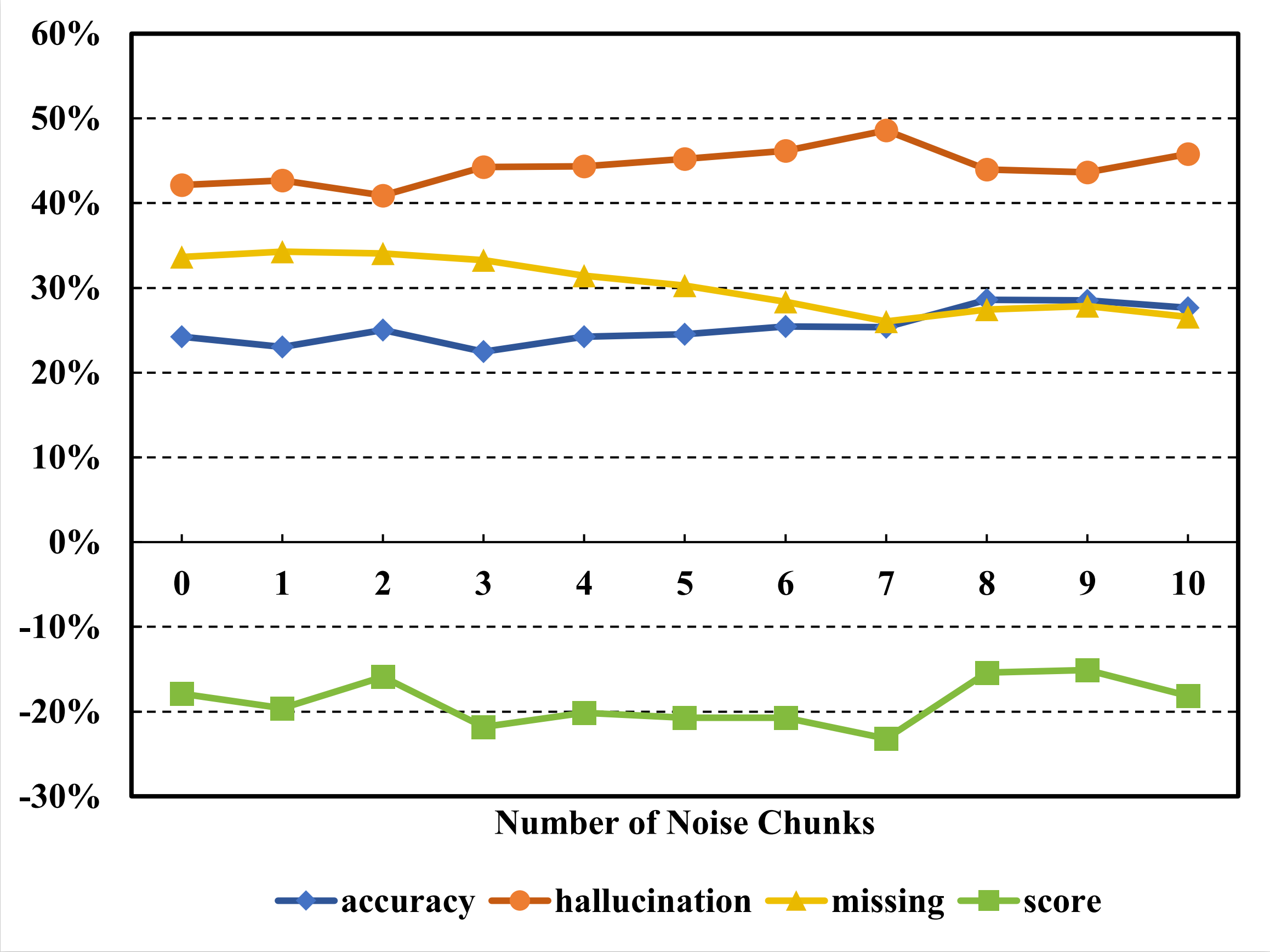
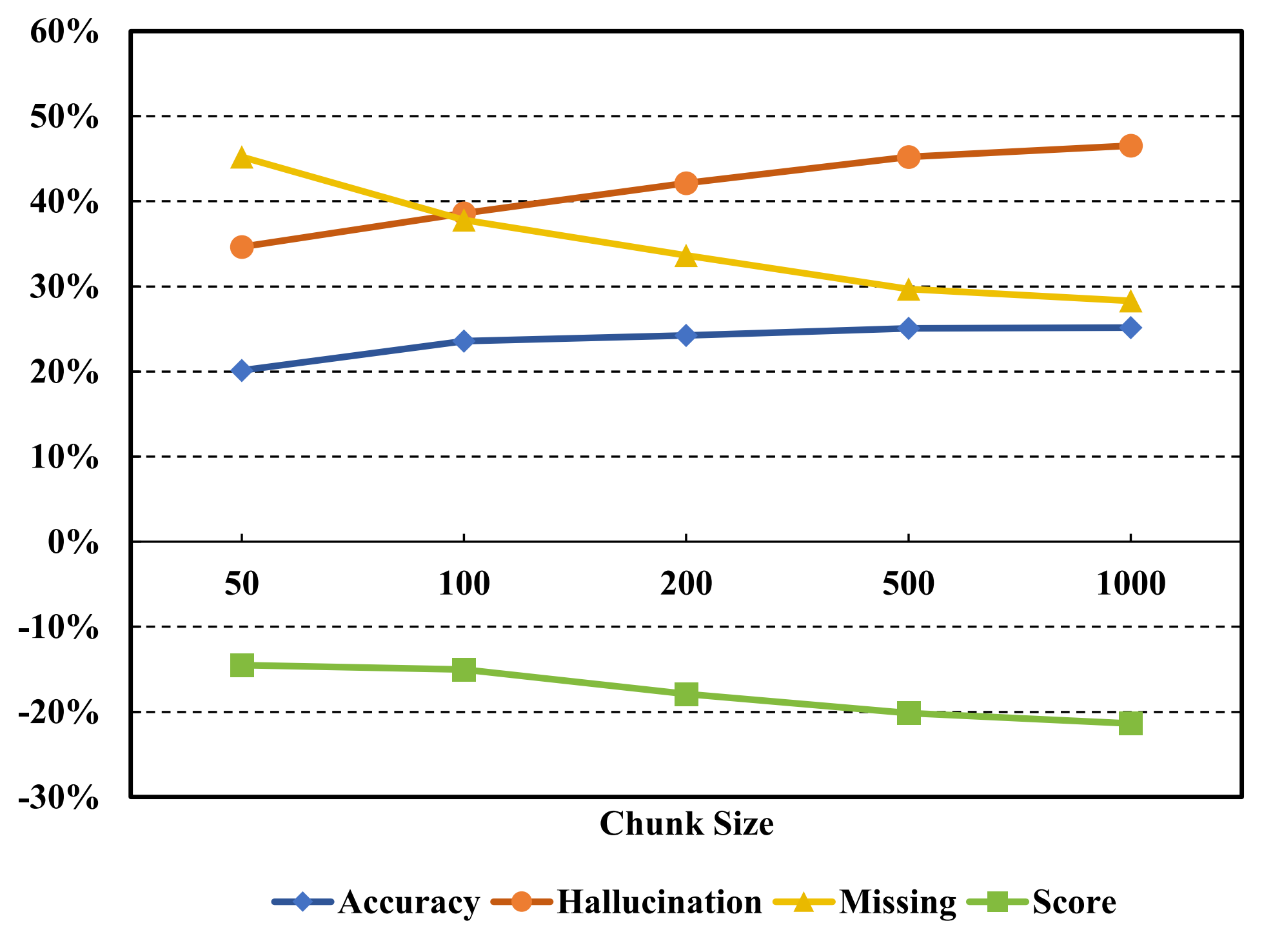
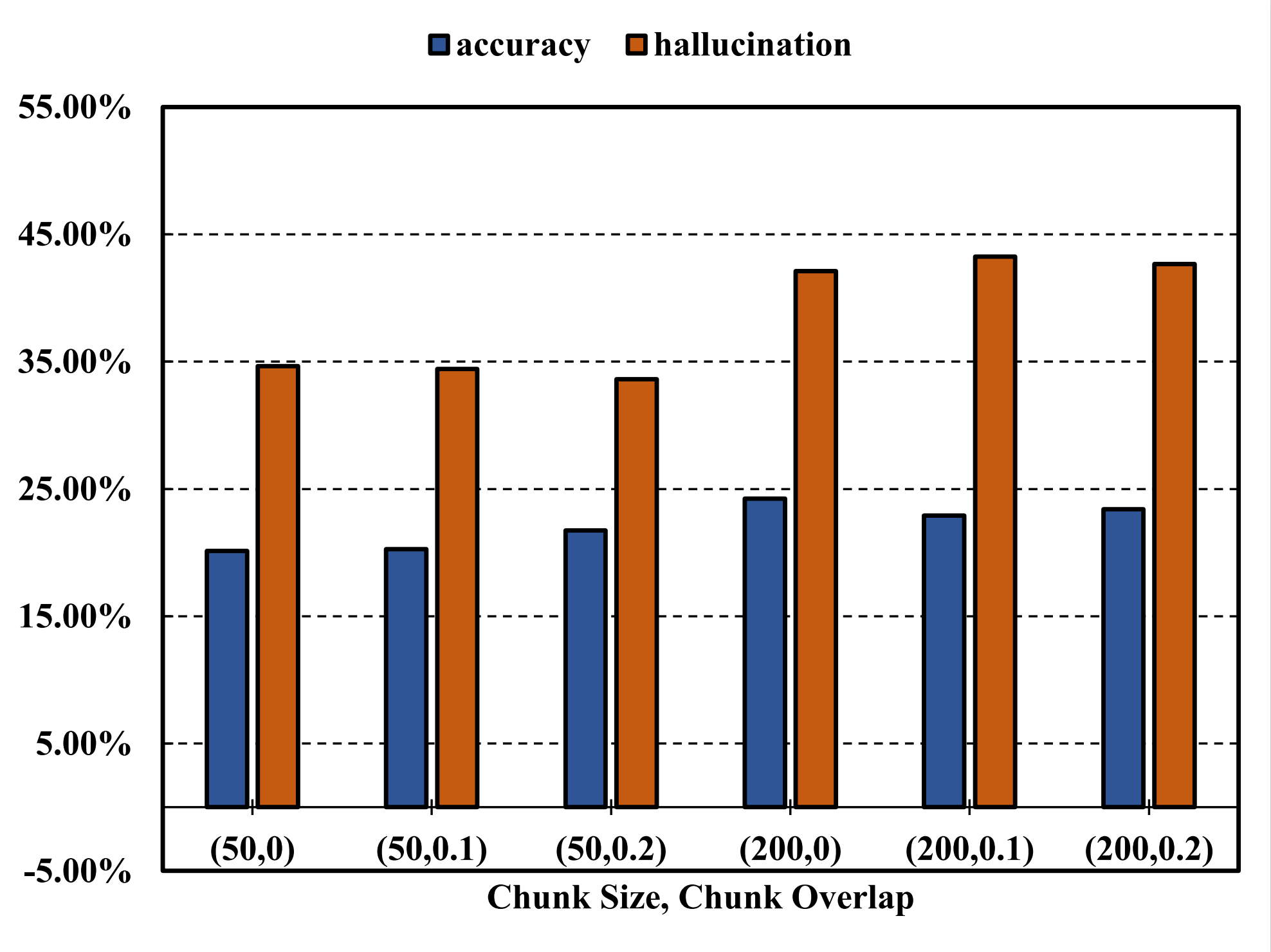
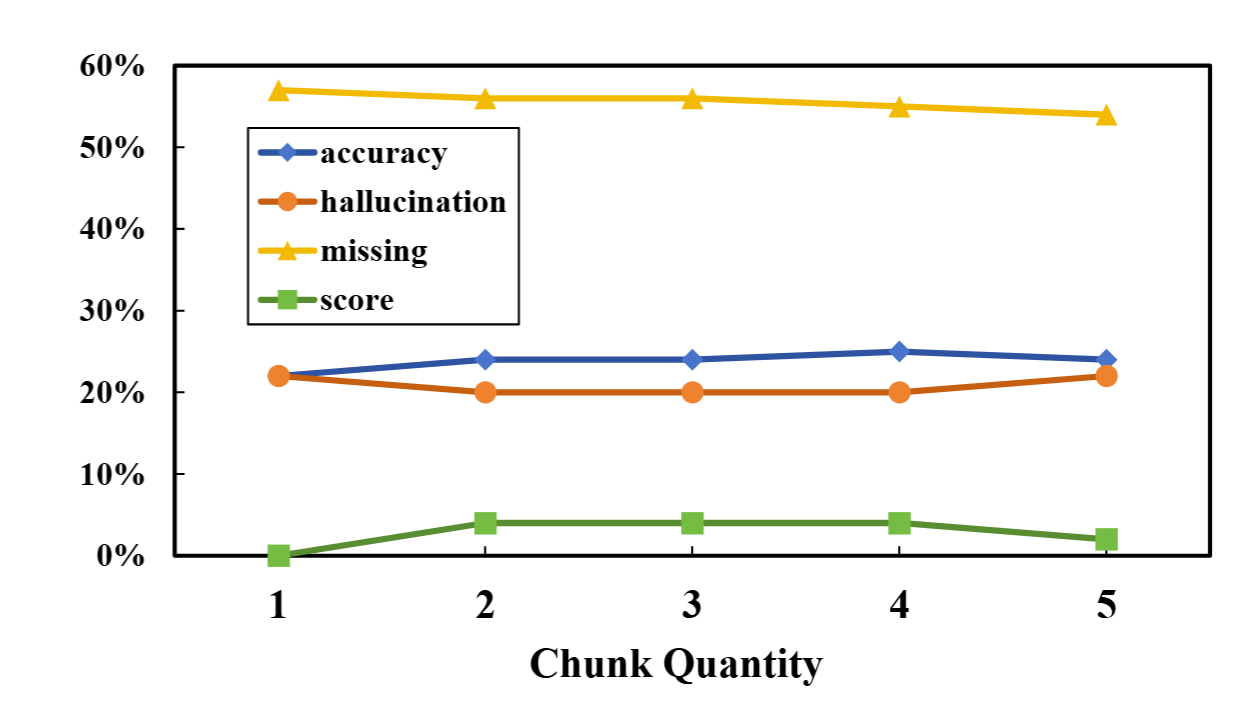
In this section, we analyze the impact of hyperparameters such as chunk size, overlap, and the number of retrieved chunks on retrieval effectiveness and response quality, offering insights for effective tuning within the PruningRAG framework.
Figure 5: Effect of chunk size on RAG performance.Figure 6: Impact of chunk overlap on RAG performance.Figure 7: Impact of chunk quantity on RAG performance.
Contact
If you have any questions, we encourage you to either create Github issues
or get in touch with us at rag_ustc@icanary.cn.